作业启动前或者作业上线后,您可以配置和修改作业资源,本文为您介绍如何配置和修改基础模式和专家模式的作业资源。
使用限制
仅SQL作业支持配置专家模式。
注意事项
作业资源配置后,需要重启作业才能生效。
操作步骤
进入资源配置入口。
登录实时计算控制台。
单击目标工作空间操作列下的控制台。
在作业运维页面,单击目标作业名称。
在部署详情页签,单击资源配置区域右侧的编辑。
修改作业资源信息。
关于TM、JM、TASK或SLOT等概念,详情请参见Apache Flink Architecture。
基础模式(粗粒度)
粗粒度是一种静态资源分配方式,您只需要给定每个TM启动所需要的总资源(CPU和JVM总内存),系统会根据每个TaskManager SLOT数(即flink conf taskmanager.numberOfTaskSlots)均匀分配所有资源。对于大多数简单作业,粗粒度即可满足要求。
配置项
说明
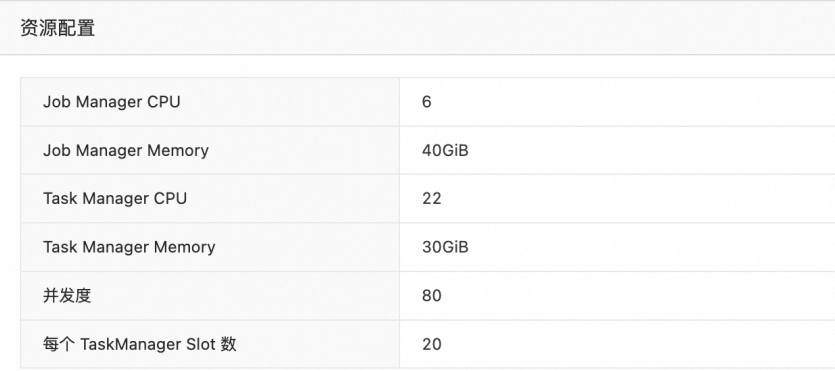
并发度
作业全局并发数。
JobManager CPU
根据Flink最佳实践,单个JM内存资源需要至少配置为0.25 Core和1 GiB,才能保证作业稳定运行。建议您配置为1 Core和4 GiB。
JobManager Memory
单位为GiB,最小值为1 GiB。
TaskManager CPU
根据Flink最佳实践,单个TM内存资源需要至少配置为0.25 Core和1 GiB,才能保证作业稳定运行。建议您配置为1 Core和4 GiB。
TaskManager Memory
单位为GiB,最小值为1 GiB。
每个TaskManager Slot数
请填写TM的Slot数。
将会涉及的推算公式如下:
作业所配置的CU数 = MAX(JM和TM的CPU总和, JM和TM的内存总和/4)。
每个作业所需IP数 = JM数(每个作业只有一个)+实际TM数。
实际TM数= MAX(⌈总CPU数/TM的CPU默认最大值⌉,⌈总内存数/TM的内存默认最大值⌉)。
总CPU数=设置的并发度/设置的每个TaskManager Slot数*设置的单个TM CPU。
总内存数=设置的并发度/设置的每个TaskManager Slot数*设置的单个TM的内存。
TM的CPU默认最大值为16 Core。
TM的内存默认最大值为64 GiB。
实际每个TM上可分配的slot数 = ⌈设置的并发数/实际TM数⌉。
例如,当并发度设置为80,每个TM Slot数设置为20,每个TM CPU设置为22 core,每个TM 内存设置为30 GiB时,配置如下图所示。
在Flink开发控制台,您会看到实际的TaskManager数为6,每个TaskManager Slot数为14。
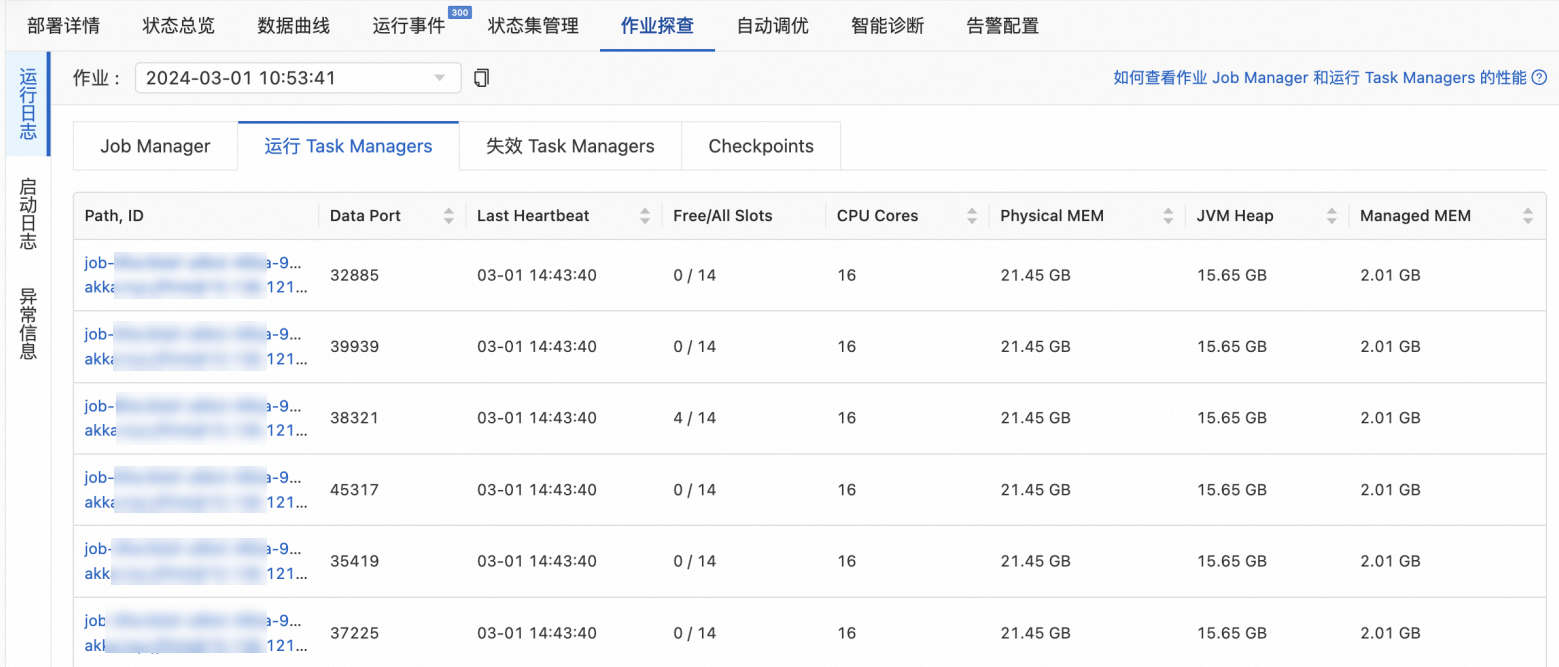
实际的TM数和每个TM的Slot数的推算过程如下:
实际TM数 =MAX(⌈总CPU数/TM的CPU默认最大值⌉,⌈总内存数/TM的内存默认最大值⌉)= MAX(⌈设置的并发数/单个TM的Slot数量*设置的单个TM CPU/16⌉,⌈设置的并发数/单个TM的Slot数量*设置的单个TM的内存/64⌉)= MAX(⌈80/20*22/16⌉,⌈80/20*30/64⌉)= MAX(⌈88/16⌉,⌈120/64⌉)= MAX(6,2) = 6。
实际TM的Slot数=⌈并发数/实际TM数⌉ = ⌈80/6⌉=14。
说明实际TM的推算逻辑需要您设置的TM的CPU和内存大于其最大默认值,才可有效。
计算比值需分别向上取整。
如果您需要提高默认TM内存和CPU的最大值,请您提交工单。
您也可以在作业部署详情页签运行参数配置区域的其他配置中设置numberOfTaskSlots参数,和界面配置每个TaskManager Slot数作用相同,但优先级更高。
专家模式(细粒度)
说明仅SQL作业支持配置专家模式。
细粒度是一种动态资源分配方式,您可以配置每个SLOT共享组(Slot Sharing Group)所需要的资源,Flink会计算出每个SLOT需要的资源规格大小,动态的从可用资源池去申请完全匹配的TM和SLOT。对于复杂作业,粗粒度可能导致资源利用率低,因此需要细粒度资源对每个算子进行精细资源控制,从而提高资源使用率,满足作业吞吐的要求。
配置基础信息
配置项
说明
JobManager CPU
根据Flink最佳实践,单个JM内存资源需要至少配置为0.25 core和1 GiB,才能保证作业稳定运行。
JobManager Memory
单位为GiB,例如,4 GiB。最小值为1 GiB。
每个TaskManager Slot数
设置TM Slot数。
配置SLOT资源
单击编辑后,资源模式选择为专家模式。
单击立刻获取。
单击SLOT框上的
 图标。
图标。
修改SLOT配置信息。
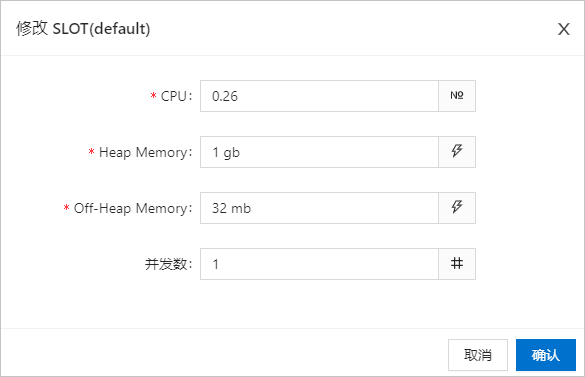
此处设置的并发数为该SLOT共享组内所有算子的统一并发数。设置完成后,系统将自动进行以下操作:
系统将自动为该SLOT共享组内的所有算子设置相同的并发数。
系统会根据作业的计算逻辑按需自动生成Statebackend、Python和Operator所需的内存,无需您手动进行配置。
建议Source节点并发度和分区数成比例,即并发度数能整除分区数。例如Kafka有16个分区,则并发度建议设置为16、8或4,这样可以避免数据倾斜。同时Source节点的并发度不宜设置太小,避免一个Source需要读取太多数据,导致出现入口瓶颈,影响作业吞吐。
建议按需配置除Source外的其他节点的并发度。流量大的节点,并发设置大一些;流量小的节点,并发设置小一些。
建议在有明确异常或者需求时,再调整Heap Memory和Off-heap Memory的大小,例如作业出现OOM或严重GC等。因为在作业正常运行时,调整Heap Memory和Off-heap Memory的大小,不会明显改变作业的吞吐量。
说明单击确定。
配置算子并发数
资源模式选择为专家模式。
单击VERTEX框上的
图标,按需为某个算子设置并发数。单击确定。
配置算子Chain策略
Chain是指多个算子被连接在一起形成的逻辑计算链。它能够提高作业的执行效率和性能,减少数据在算子之间的传输和序列化开销。不过有时,可能需要将Chain断开,以便更好地控制作业的执行流程和性能。您可以按照如下步骤配置算子Chain策略:
资源模式选择为专家模式。
单击
图标。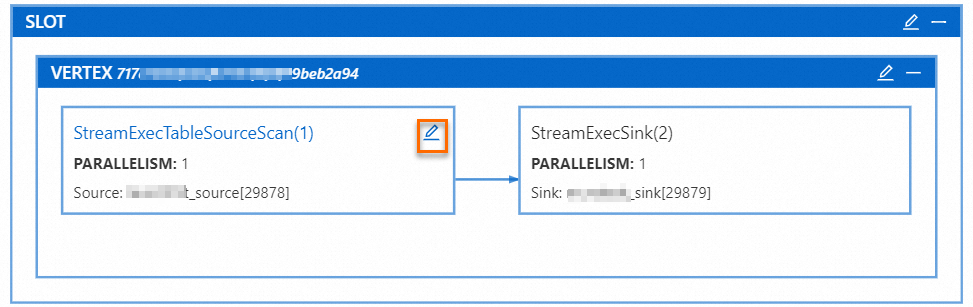
修改Chain策略。
Chaining策略
说明
ALWAYS(默认值)
算子始终可以和上下游算子Chain一起。
HEAD
当前算子作为Chain的头节点,只和上游算子断开Chain,下游节点仍和当前算子Chain在一起。
NEVER
当前算子不会与上下游算子进行Chain。
单击确定。
配置算子的资源
默认情况下,所有算子都放在一个SLOT共享组内,因此您无法为每个算子单独修改资源配置。如果您需要对单独的算子设置资源,需要配置对应的运行参数后让每个算子有自己独立的SLOT,这样就可以直接在对应的SLOT上设置算子的资源。具体的算子资源设置步骤如下:
在作业部署详情页签运行参数配置区域的其他配置中添加如下参数信息。
table.exec.split-slot-sharing-group-per-vertex: 'true'重启作业。
在作业部署详情页签资源配置区域,单击编辑后,资源模式选择为专家模式后,单击重新生成。
单击目标算子对应SLOT框上的
图标后,修改算子资源。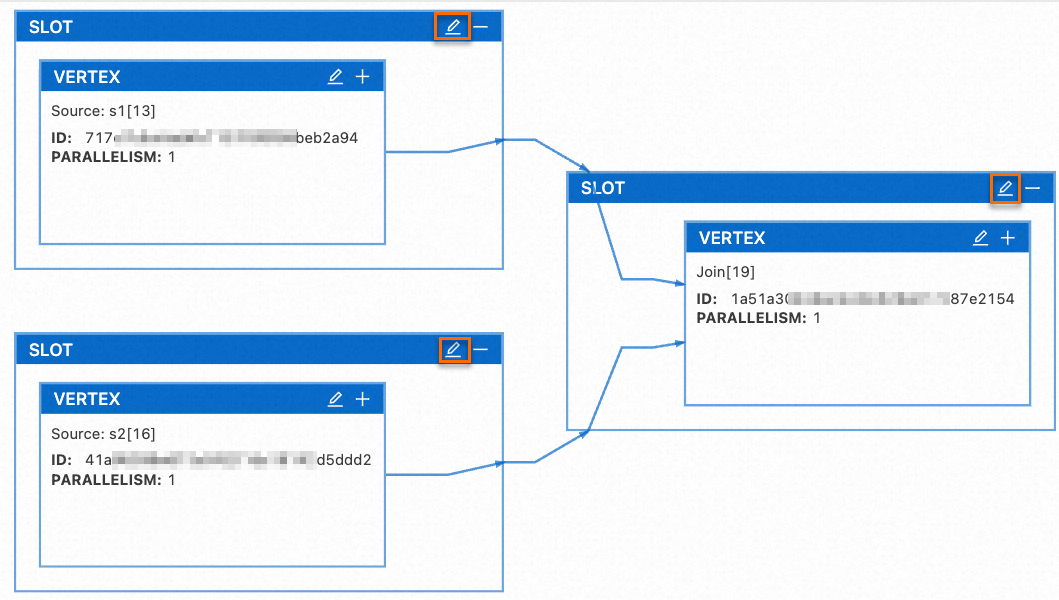
单击确定。
单击保存。
相关文档
资源优化技巧,详情请参见高性能Flink SQL优化技巧。
如果不想手动调节资源,可以使用自动调优,系统会自动完成资源调节,详情请参见配置自动调优。
作业的基础配置、运行参数配置和日志配置,详情请参见配置作业部署信息。
您可以通过Flink Advisor作业智能诊断服务帮您监控作业健康状况,详情请参见作业智能诊断。
- 本页导读 (1)